The context window is the new database
Enterprise AI projects keep failing at the same point: not the model, not the engineering, but the data supplied to the model at inference time. The context window has become the most critical layer in AI system design, and most teams are treating it like a skip bin. This piece argues for treating it with the same architectural rigour you'd give a production database.
The model is not the bottleneck
There's a persistent belief in enterprise AI that the next model release will solve the quality problem. GPT-5 will hallucinate less. Claude 4 will reason better. Gemini will finally understand your domain.
I keep seeing this play out with clients. They upgrade to the latest model, run the same messy data through it, and get the same disappointing results. Then they blame the model. But the pattern is consistent: when you clean up what goes into the context window, output quality jumps dramatically, regardless of which model you're running. Anthropic's own prompt engineering documentation makes this point explicitly. So does every serious benchmark. The quality of what goes in matters more than the sophistication of what processes it.
Google DeepMind's work on context distillation points in the same direction. The research community is broadly aligned here: model capability has outpaced the data infrastructure feeding it. We're past the point where model upgrades are the bottleneck.
"The most common failure mode in enterprise AI isn't model capability. It's context contamination."
— Token Theory
What happens when context is unstructured
Here's a scenario I see constantly. A customer service agent backed by an LLM needs to answer a question about a client's account. The relevant information is spread across Salesforce, Xero, HubSpot, and three internal spreadsheets. The standard approach: dump whatever you can retrieve into the context window and hope the model sorts it out.
What actually happens is the model receives 15,000 tokens of duplicated records, conflicting dates, incomplete document fragments, and metadata noise. It produces a confident, articulate, and subtly wrong answer. Because the data it was reasoning over was subtly wrong.
This is the part that catches people out. The output looks good. It reads well. But when you trace it back to the source data, you find the model has confidently merged two different John Smiths, or cited a financial figure from last quarter as if it were current. The failure mode isn't obvious until it hits production.
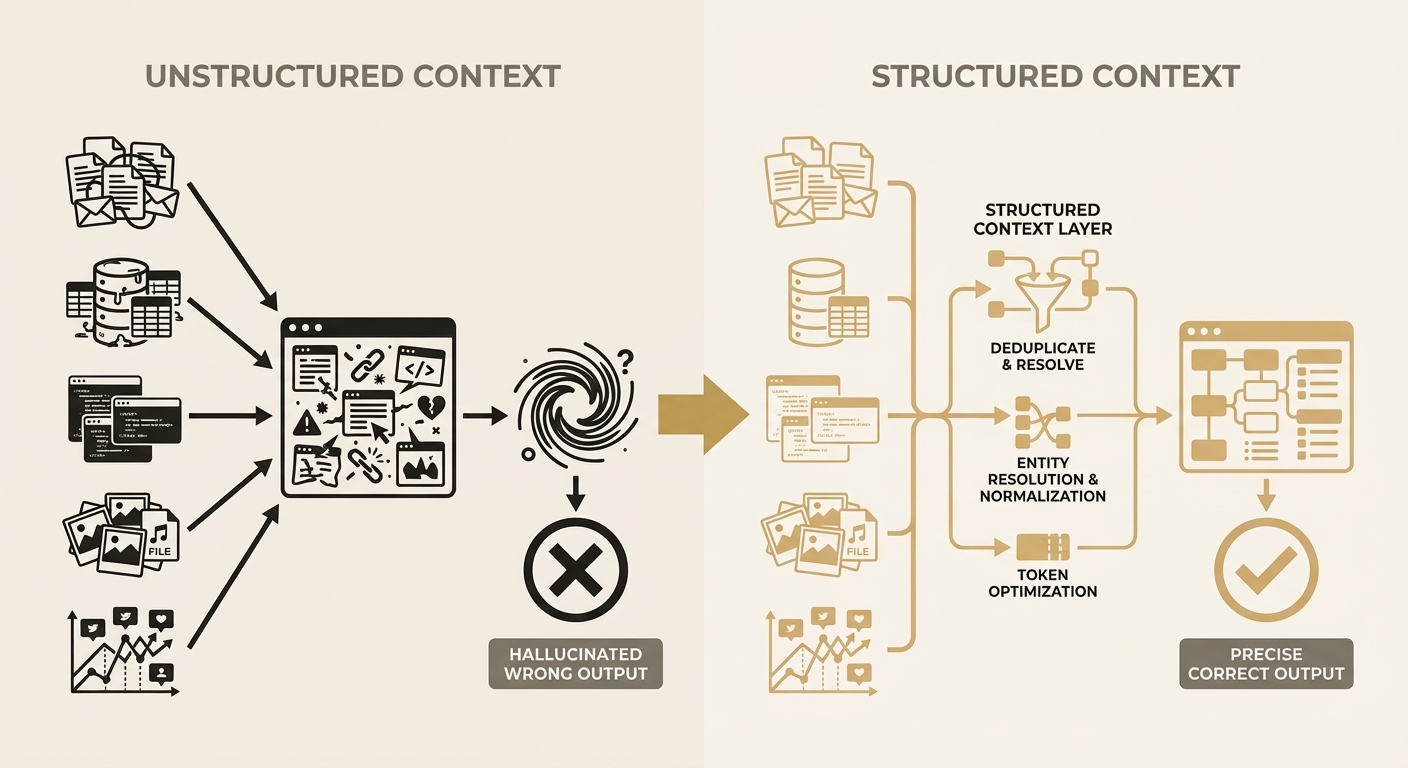
Unstructured vs. Structured Context
The context window as an architectural concern
Database architects spend years on schemas, normalisation, indexing, and query optimisation. The context window deserves the same attention. Functionally, it is the database the model queries at inference time. Except it has no schema, no indexing, no normalisation, and no query planner. Everything enters as flat text, and the model reconstructs meaning from scratch on every single request.
This is where the concept of a context layer comes in. Instead of treating the context window as a dumping ground, you design an intermediate layer that:
- Resolves entities across source systems (is "John Smith" in Salesforce the same as "J. Smith" in HubSpot?)
- Deduplicates records while preserving provenance
- Structures information hierarchically, with summaries first and detail on demand
- Optimises for token efficiency without losing semantic fidelity
- Maintains temporal ordering so the model understands what happened when
Token economics reinforce the argument
There's a straightforward economic case too. At current pricing (roughly $3-15 per million input tokens for frontier models), every token of noise has a direct cost. An enterprise running 10,000 AI-assisted interactions per day with 5,000 tokens of unnecessary context is burning $150-750 per day on noise. Over a year, that's $55K-$275K in wasted inference cost, before you even count the downstream cost of wrong answers.
Now, prompt caching has made large context windows cheaper. That's real progress. But caching a disorganised mess still produces disorganised reasoning. Caching makes the noise cheaper to send; it doesn't help the model think more clearly. When you structure data before it enters the window, you can deliver the same semantic payload in 40-60% fewer tokens. That's a cost saving and an accuracy improvement.
What this means in practice
I've seen this pattern repeat across every engagement. The client arrives thinking they need a better model, a fancier embedding, or a more sophisticated RAG pipeline. What they actually need is someone to sit down with their data, map the entity relationships across their systems, and build a context layer that gives the model clean, structured, deduplicated information.
It's unglamorous work. It doesn't make for exciting demos. But it's the difference between an AI system that impresses in a proof-of-concept and one that actually works in production, at scale, for months without someone babysitting it.
Further reading
- Anthropic, "Long Context Prompting Tips" (docs.anthropic.com) — practical guidance on structuring context for better model performance
- Liu et al., "Lost in the Middle: How Language Models Use Long Contexts", TACL 2024 — foundational research on how context position affects model attention
- Google DeepMind, research on context distillation — compressing context while preserving reasoning quality
- Gartner, "Top Strategic Technology Trends for AI", 2025 — data quality consistently ranked as primary barrier to enterprise AI adoption
- Simon Willison (simonwillison.net) — ongoing practical analysis of LLM context management and prompt engineering
Related articles
RAG and agentic search both have a context problem
Standard RAG retrieves snippets that often cut off mid-thought, losing the surrounding context that gives information its meaning. Agentic search swings the other way and floods the context window with everything it can find. Neither approach solves the fundamental issue: you need a structured context layer that delivers the right information, at the right depth, without the noise.
Read more ThesisAgentic development changes the economics
The traditional consultancy model charges $500K+ to build what can now be delivered in weeks. Anthropic is shipping enterprise-grade Claude features on a weekly cadence. The tooling has fundamentally changed. We're not cutting corners; we're building on a platform that didn't exist 12 months ago. The result is bespoke tools at a fraction of enterprise advisory pricing, without the 18-month delivery timelines.
Read moreInterested in working together?
Let's discuss what's possible for your organisation.
hello@tokentheory.ai