RAG and agentic search both have a context problem
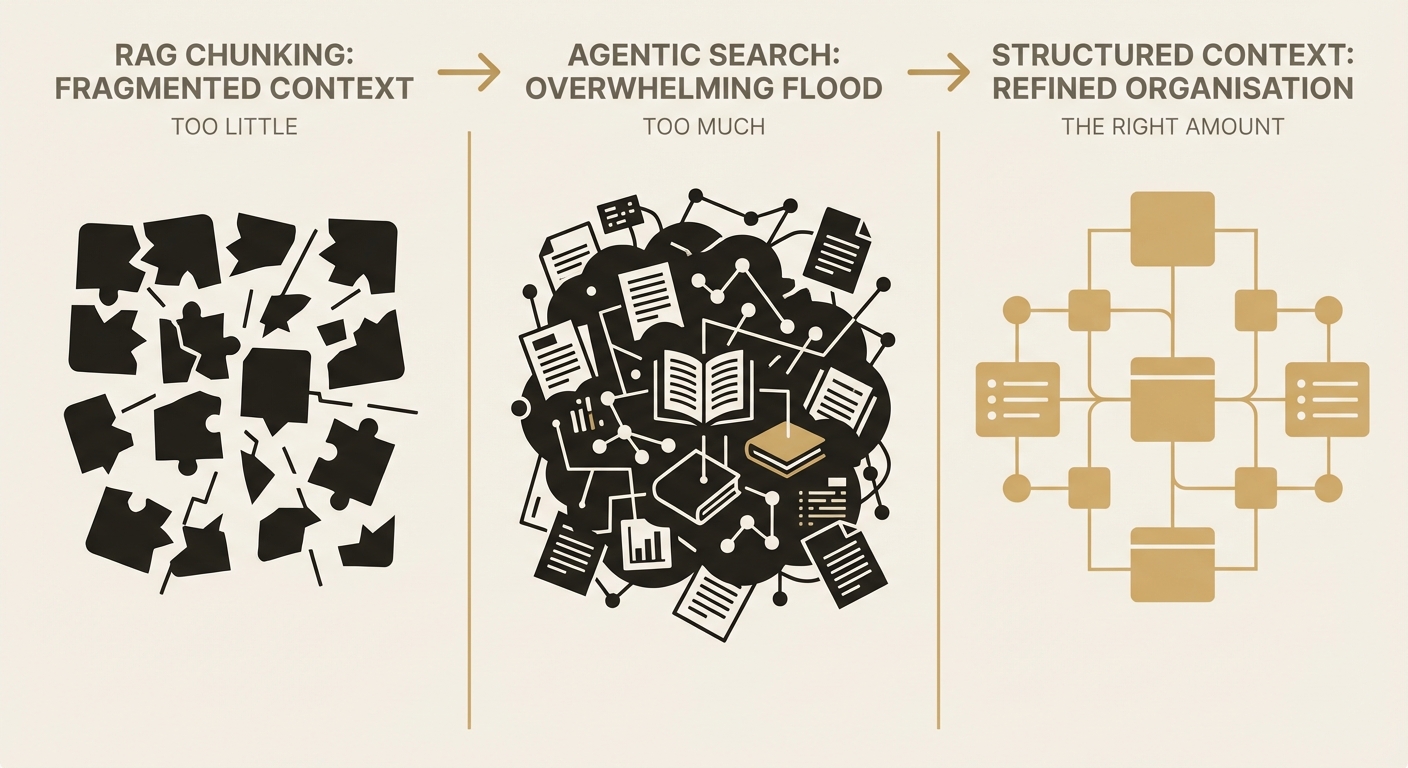
RAG and agentic search are two opposing responses to the same problem: getting the right information into an LLM's context window. RAG gives you too little (fragmented chunks). Agentic search gives you too much (information flooding). Both assume the problem is retrieval. It isn't. It's data architecture.
The RAG chunking problem
RAG has become the default architecture for enterprise AI, and the core idea is sound: instead of relying on the model's training data, retrieve relevant documents at query time and inject them into the context. In practice, this means splitting documents into chunks (typically 256-1024 tokens), embedding them as vectors, and retrieving the top matches at inference time.
The problem is in the chunking. When you split a document into fixed-size segments, you cut across semantic boundaries. A paragraph explaining a financial policy gets split mid-sentence. A table loses its headers. A list of conditions gets separated from the clause they modify. The retrieved chunk scores well on vector similarity but arrives semantically incomplete.
"Vector similarity measures topical relevance, not semantic completeness. A chunk can be maximally similar to a query while being minimally useful for answering it."
— Token Theory
This is well-documented in the RAG community. A significant proportion of retrieved contexts end up "semantically orphaned," as practitioners describe it: relevant to the topic but missing the surrounding context needed for accurate reasoning. You can increase chunk overlap to mitigate this, but that introduces redundancy and inflates token costs without proportionally improving accuracy.
To be fair, techniques like semantic chunking, GraphRAG, and document hierarchies have made real progress here. But they're ultimately better implementations of the same retrieval paradigm. They improve how you find and cut the data. They don't solve the underlying problem of what that data looks like before the search even starts.
The agentic search flooding problem
Agentic search emerged as a response to RAG's limitations. Instead of retrieving pre-chunked fragments, an agent iteratively searches, reads, and synthesises information, more like how a human researcher would approach a complex question. Systems like Perplexity, OpenAI's deep research mode, and various enterprise agent frameworks take this approach.
You get significantly more context this way, often filling 50-80% of the available window. And this is where a different problem shows up.
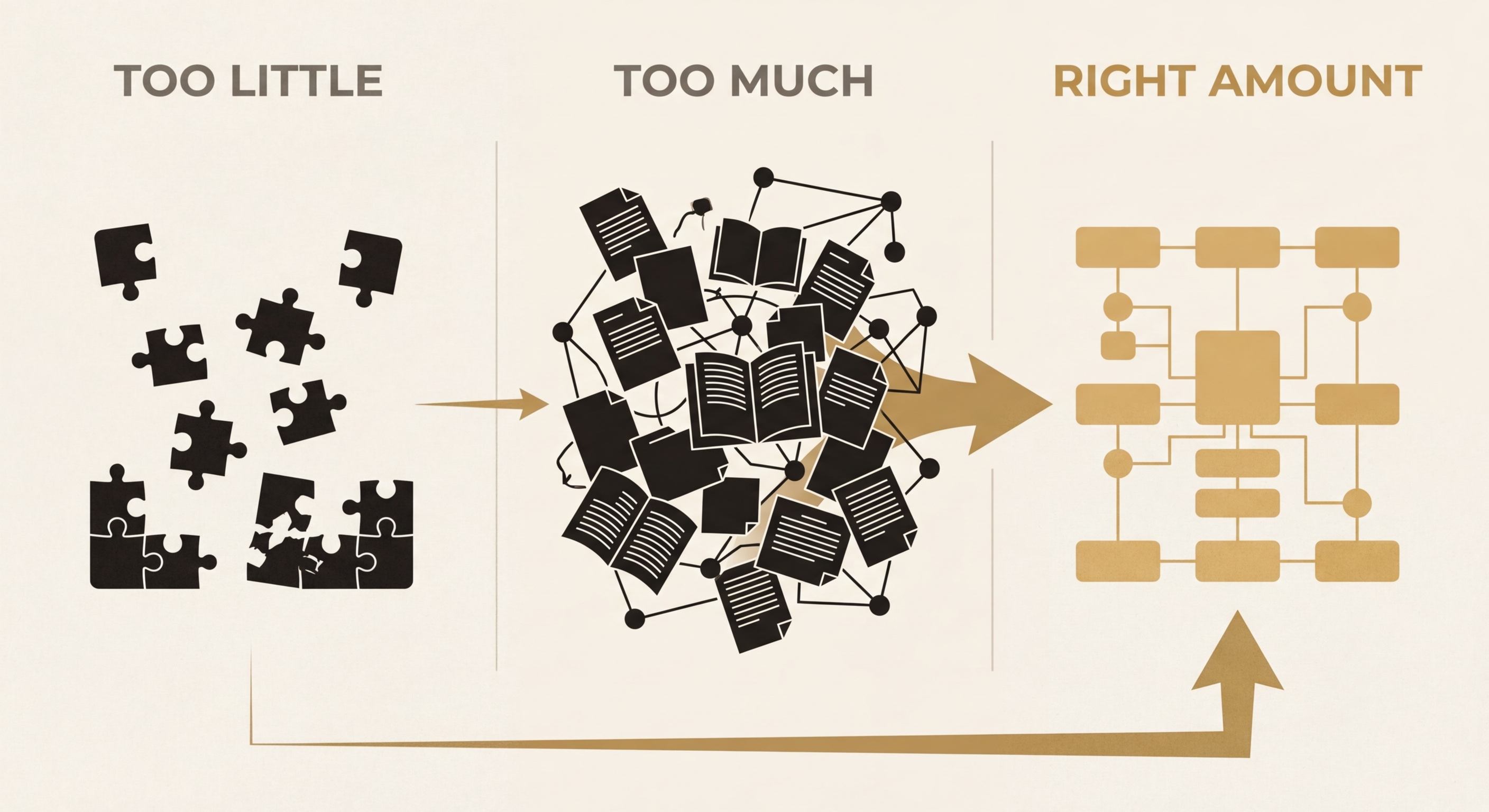
The Context Spectrum
Liu et al.'s "Lost in the Middle" paper (published in TACL, 2024) showed conclusively that LLMs struggle to use information placed in the middle of long contexts. Performance degrades when the answer is buried among large volumes of supporting text. The model doesn't ignore the information; it just pays less attention to content that isn't near the beginning or end of the window.
It's worth noting that models like Claude can reliably retrieve a single fact from a 100K+ token window. The "needle in a haystack" benchmarks prove that. But there's a gap between finding one fact and reasoning across multiple related facts scattered through a large context. Multi-hop reasoning, connecting several pieces of information to reach a conclusion, is where performance degrades as the window fills with noise. The model has everything it needs. It just can't effectively synthesise across it all.
Why both approaches fail at the same point
RAG and agentic search differ in how much they retrieve, but they share a fundamental assumption: that the quality problem can be solved at the retrieval layer. Find the right documents, and the model handles the rest.
This assumption breaks down because retrieval is a search problem, and search is not the same as understanding. A search system can find relevant documents. What it can't do:
- Resolve entity conflicts across source systems ("John Smith" in CRM vs "J. Smith" in billing)
- Deduplicate information that appears in multiple documents in different forms
- Structure hierarchical relationships (this policy overrides that one, this amendment supersedes that clause)
- Order temporal sequences correctly (this happened before that, making the third event the most current)
- Distinguish between canonical information and draft or outdated versions
These are data architecture problems, not search problems. They require a layer between the source systems and the context window that understands the shape of the data, not just its relevance.
The structured context layer
What we build at Token Theory is a structured context layer: an intermediate data architecture that sits between source systems and the LLM. It does the unglamorous work of entity resolution, deduplication, hierarchical structuring, and token optimisation before any data reaches the model.
The important distinction is that this layer isn't a retrieval system. It's a data product. It's maintained, versioned, and quality-controlled like a database, not generated on-the-fly like a search result. When a model needs context, it queries a pre-structured representation of the organisation's data rather than running a live search across raw source systems.
This trades retrieval flexibility for context quality. You can't ask arbitrary questions across all your data (that's what agentic search is for). But for the queries that matter, the ones your AI system handles hundreds of times a day, the context is precise, deduplicated, correctly ordered, and token-efficient.
Further reading
- Liu et al., "Lost in the Middle: How Language Models Use Long Contexts", TACL 2024 — foundational research on context window position effects
- Anthropic, "Long Context Prompting Tips" (docs.anthropic.com) — practical guidance on structuring prompts for long-context models
- LangChain blog, "Agentic RAG" series — good overview of the evolution from naive RAG to agent-driven retrieval
- Galileo, "RAG Quality Metrics", 2024 — independent benchmarking of retrieval accuracy and chunking strategies
- Jerry Liu (LlamaIndex), writing on structured data extraction and hierarchical indexing for RAG systems
Related articles
The context window is the new database
GPT-5 won't fix your hallucination problem. Neither will Claude Opus. The models are already good enough. The bottleneck is what you feed them. When fragmented, poorly structured data gets shoved into context windows with no architecture, you get confident-sounding nonsense. The fix isn't a better model. It's better data.
Read more ThesisAgentic development changes the economics
The traditional consultancy model charges $500K+ to build what can now be delivered in weeks. Anthropic is shipping enterprise-grade Claude features on a weekly cadence. The tooling has fundamentally changed. We're not cutting corners; we're building on a platform that didn't exist 12 months ago. The result is bespoke tools at a fraction of enterprise advisory pricing, without the 18-month delivery timelines.
Read moreInterested in working together?
Let's discuss what's possible for your organisation.
hello@tokentheory.ai